
语音和语言技术中心 demo 演示系统
Center for Speech and Language Technologies
信息技术研究院 · 清华大学 Research Institute of Information Technology · Tsinghua University

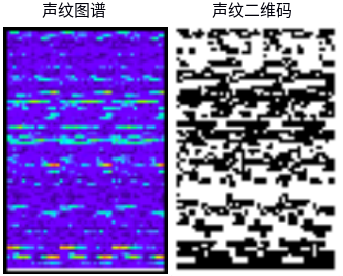
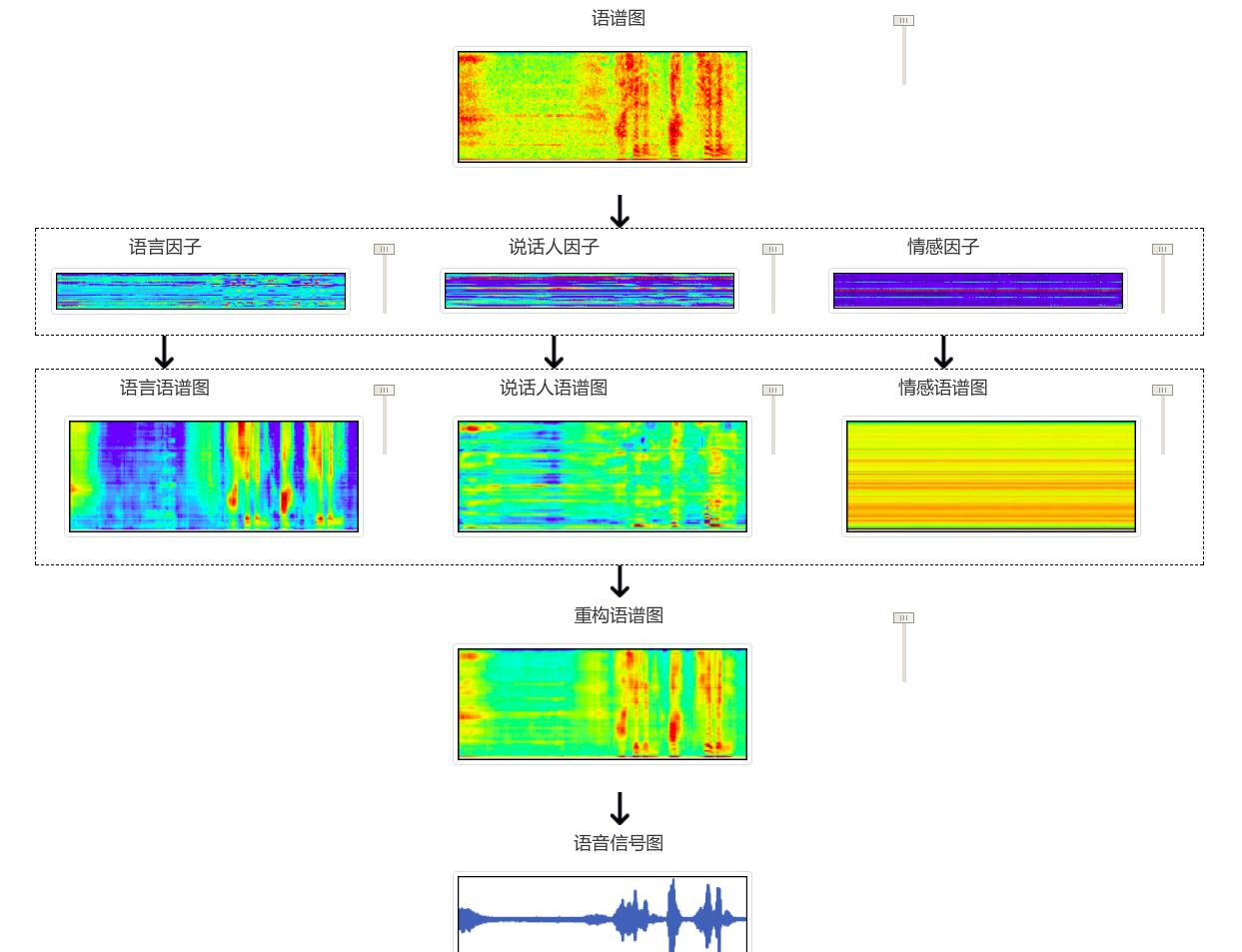
联系我们


地址:北京市海淀区清华大学FIT楼1-303房间
电话/传真:010-62796589
邮编:100084
E-mail:cslt@mail.tsinghua.edu.cn
© 清华大学 FreeNeb 老铁科技 2024